Rapport des résultats de la PoC
Sommaire
- Rapport des résultats de la PoC
Objet de document
Ce document détaille l'architecture logicielle retenue, les décisions architecturales, les choix technologiques et détails d'implémentation pour la preuve de concept. Ce document reprend le contexte dans le quel ce PoC a été mené et amène ses conclusions quand à la faisabilité d'un système de réservation d'urgence.
Historique de révision
| Numéro de version | Auteur | Description | Date de modification |
| ----------------- | -------- | ------------------ | -------------------- |
| 1.0.0 | Y. Talon | Rédaction initiale | 08/04/2025 |
Introduction
Contexte
Un consortium composé de quatre entreprises leaders s’est formé pour mutualiser leurs efforts, données, applications et feuilles de route, afin de développer une plateforme de nouvelle génération, centrée sur le patient. Celle-ci vise à améliorer les soins de base tout en étant réactive, opérationnelle en temps réel et capable de prendre des décisions critiques en situation d’urgence, en tenant compte de toutes les données disponibles.
Objectif de la PoC
La mise en œuvre d'une preuve de concept pour le système d'intervention d'urgence en temps réel par l'équipe d'architecture métier du consortium MedHead permettra :
-
D’améliorer la qualité des traitements d'urgence et de sauver plus de vies.
-
De gagner la confiance des utilisateurs quant à la simplicité d'un tel système.
Description du projet
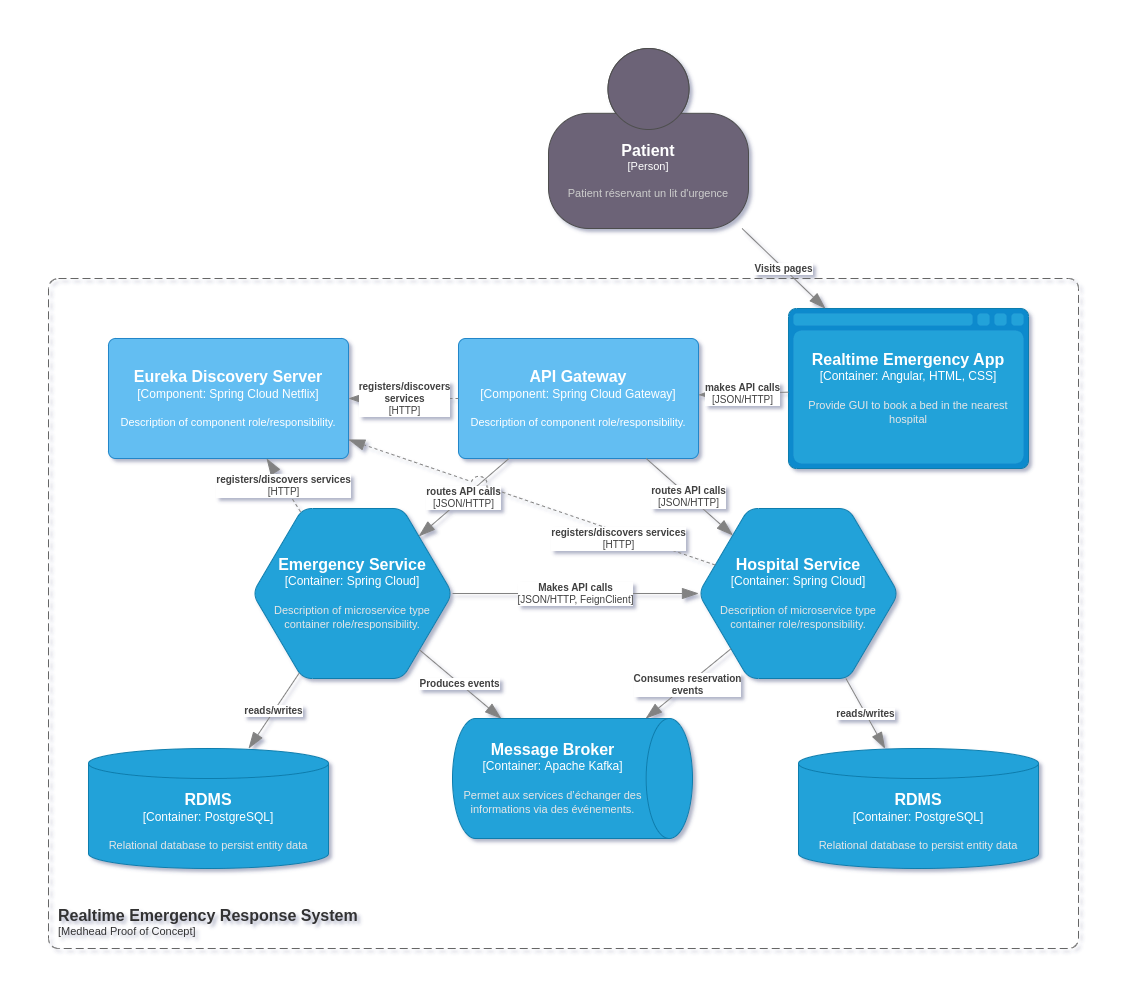
Architecture logicielle
Stack technologique
-
Langages : Java, Typescript, HTML, CSS
-
Frameworks : Spring Boot, Spring Cloud, Angular 19
-
Tests : Junit, JMeter
-
Build : Maven, Vite
-
Intégration continue : Git, Github Actions,
-
Base de données : PostgreSQL
-
Event Driven : Kafka
Composants de la PoC
-
Netflix Eureka Discovery Server : Composant clé dans l'architecture micro-service, il permet de :
-
Permet aux services de se trouver et de communiquer entre eux sans avoir à coder en dur le nom d'hôte et le port.
-
Assurer le load balancing entre plusieurs instances d'un même service dans le cadre d'une mise à l'échelle.
-
Spring Cloud Gateway : Centralise les requêtes HTTP entrantes et sortantes de sorte à offrir 1 seul point d'entrée pour les clients d'API de la PoC (App frontend, client d'API, tierce partie) - Dispose d'une configuration de route pour fournir aux clients d'API une interface homogène, sans besoin de spécifier le nom du micro service responsable des endpoints à consommer.
Example : https://mydomain.com/v1/hospitals est routé en interne vers https://mydomain.com/hospital-service/v1/hospitals
Les services sont contactés grâce à leur nom et non leur URL. C'est grâce au Discovery Server que les URL des micro services sont connus. De cette manière, ils peuvent être mis à l'échelle en routant dynamiquement les requêtes pour répartir la charge.
-
Hospital Service : Regroupe le domaine et les sous-domaine liés aux hopitaux : détails sur spécialisations médicales, hopitaux, disponibilité d'un lit, prise en compte
-
Agit en tant que Consumer : S'abonne à un topic d'événement "Bed-reservation-booked" afin de décrémenter le nombre de lit disponible en fonction de l'hopital et la spécialisation médicale.
-
Emergency Service : Responsable de la prise de rendez-vous. Ce service communique via FeignClient à Hospital Service pour connaître les informations les hopitau et spécialisations, mais également pour connaître la dispnobilité d'un lit avant un réservation
-
Agit en tant que Producer : A chaque réservation complétée, le service génère un évènement envoyé aux broker d'évènement (kafka dans notre cas) afin qu'il soit consommés par d'autres services (Hospital service, outils de data analyse par exemple).
-
Message Broker Kafka : Permet aux services d'échanger des informations via des événements. De cette manière plusieurs services interdépendants peuvent échanger en temps réels des informations sans que ces derniers soit développés dans le même langages ou hébergés sur la même plateforme.
-
Base de donnée relationnelle PostgreSQL : Responsable de la persistance des données liées à chaque domaine ou sous-domaine métier. En Production, chaque microservice dispose de sa propre instance de base de donnée. Pour l'environnement de développement, une seule base de donné est démarrée, mais chaque service initialise et utilise son propre schéma, isolé des données des autres services.
Gestion des migrations de données
La gestion des migration de la couche de persistance est déléguée à un outil dédié, Liquibase. Avec cet outil de Database Change Management, nous facilitons ainsi l'intégration continue et la refactorisation de la base de données et ses tables.
La persistance n'est plus qu'un couche abstraite qui lie nos données avec les entités de notre domaine métier.
Gestion des branches avec Trunk-Based Development
Dans le cadre de notre démarche d’intégration continue et de livraison continue, nous avons retenu la stratégie de gestion de branche basée sur le trunk-based development. Cette approche s’aligne étroitement avec les exigences de livraisons fréquentes, fiables et de haute qualité. Nos principales motivations sont les suivantes :
-
Facilitation de l’intégration continue : en centralisant les développements sur une branche unique (
main), les contributions sont intégrées de manière régulière, réduisant ainsi significativement les risques de conflits complexes lors des fusions. -
Accélération du cycle de livraison : Un seul code constamment à jour, stable et déployable permet des déploiements plus fréquents, tout en minimisant les retards et les incertitudes en fin de cycle.
-
Renforcement de la qualité par les tests automatisés : Chaque modification (pull request, merge sur la branche principale) est soumise à une batterie de tests, évaluant rapidement les non-régressions et la stabilité de l'état du système.
-
Amélioration de la collaboration au sein de l’équipe : le travail sur une base commune favorise une meilleure coordination, une plus grande transparence et une compréhension partagée de l’état du projet.
-
Simplification de la gestion des branches : En évitant la multiplication des branches longues, les incréments sont rapidement ajoutés à la branche principale, favorisant un historique et un suivi plus claire, et une seule voie pour la mise en production.
La gestion des branches principales reste proche d'une gestion Gitflow :
-
mainversionne l'état du système tel qu'il est en environnement de production. Cette branche est très protégée afin d'éviter toute changement provoquant un incident / bug en production. -
developest une branche dédiée à l'environnement de staging/préproduction. Basée surmain, Cette branche a une visée de qualification en fin de cycle de test, avant de pousser les changements sur la branche principale. Cette branche est protégée, et nécssite que la CI réussie pour que les changement soient appliqués, comme pourmain. Cette branche ne peut avoir trop de commit d'avance sur lamainsous peine de rendre cet environnement non ISO avec la production. -
les branche
feature/refacto/fix/chore/autresont également des branches à durée de vie très courte en fonction des travaux en cours. Ces branches peuvent être déployée dans un environnement éphémère de test pour valider les changements réalisés.
Architecture Design Patterns
-
Architecture Microservice :
-
Service déployable indépendamment des autres et de manière décentralisée.
-
Mise à l'échelle facilitée pour les services qui ont la plus forte utilisation.
-
Équilibrage de charge entre les différentes instances d'un même service
-
D'un point de vue métier, la logique des sous-domaines business sont encapsulées dans chaque micro-services, avec des frontières claires et définies.
-
Dans notre contexte actuelle de projet agile, la maintenance de chaque sous-domaine est facilitée pour les équipes de développement, en réduisant les risques d'incidents lors d'évolutions futures.
-
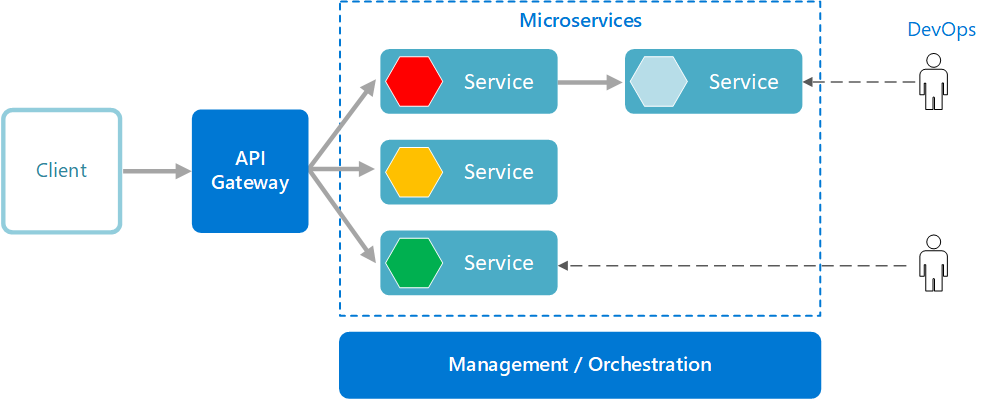
Note importante : Notre API Gateway devient de fait un Single Point of Failure (SPOF). Pour assurer une haute disponibilité et une tolérance au panne, la mise en place d'un Reverse Proxy ainsi qu'un équilibrage de charge permettront d'assurer la fiabilité de notre API Gateway.
- Gateway Aggregation and Routing : Au lieu de proposer aux clients d'applications plusieurs points de terminaison, seule une porte d'entrée est accessible
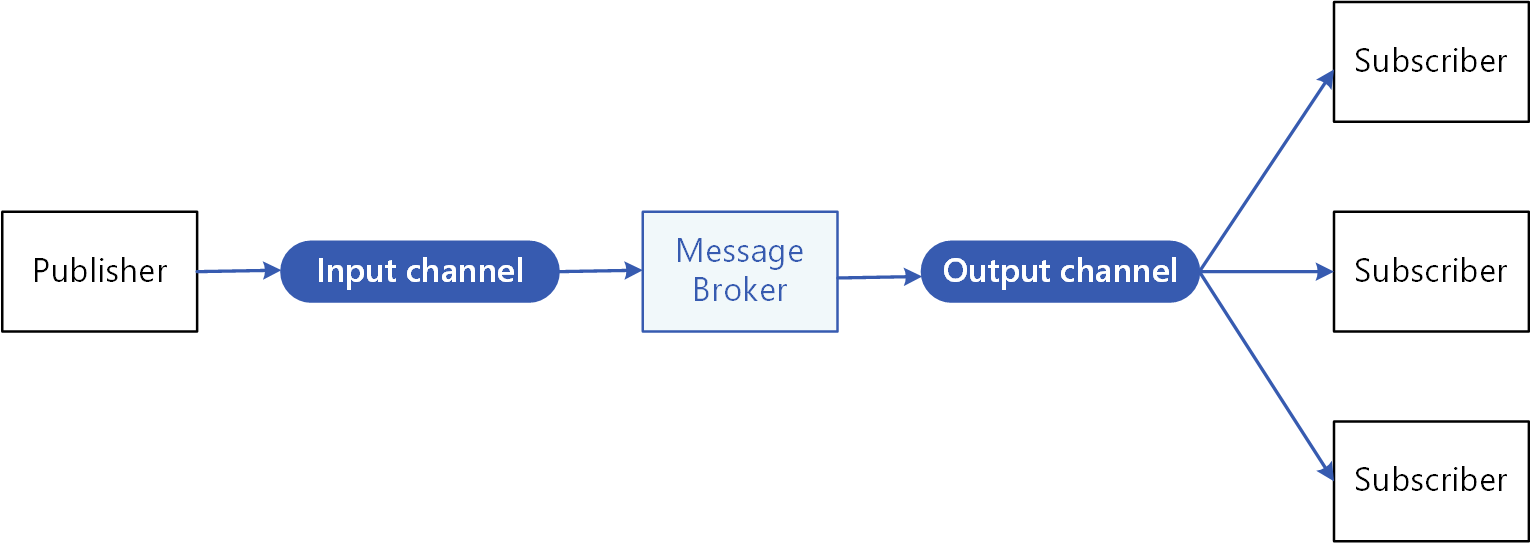
- Event-Driven & Publisher/subscribers patterns :
Composant logiciel permettant de transmettre des informations et événements, où d'autres systèmes peuvent être appairé sans qu'il ne soient implémenté dans les mêmes langages ou sur la même plateforme d'hébergement. que notre PoC.
Grâce à Spring Cloud Stream & StreamBridge, nos microservice se binde (s'appairent) avec un message broker via le fichier de configuration.
De cette manière, notre implémentation est découplée du système de messaging
Intégration Continue
Dans une démarche Agile, DevOps, de qualité, nous intégrons en continu nos changements grâce à une stratégie de test Shift Left. La prise en compte des tests en faite le plus en amont des développement ou durant, de sorte à toujours garder un état déployable en production de notre système.
Tests unitaires
Les tests unitaires s'assurent que les méthodes principales de notre code soient validées. Si ces tests échouent, les mises à jours de notre code principal sont bloquées jusqu'à ce que les test passent.
L'objectif de ces test est de vérifier que nos Features répondent aux besoins exprimés, ainsi que de tester les edge cases comme des ressources introuvables.
- Gestion des hôpitaux et des disponibilités
- Gestion des réservation

Tests d'intégration (Interconnexion, client d'API)
Les tests d'intégration couvrent le bon fonctionnement de chaque service applicatif ainsi que les points de terminaison REST de notre API. Ces tests sont à la fois automatisés et manuels via un client d'API.
Lorsque nous lançons nos services, nous nous assurons que
-
La base de donnée relationnelle est accessible est initialisée avec le schéma de données.
-
Le Binding au Message broker est opérationnelle, pour produire les messages comme pour s'abonner au topic du message broker.
Nous contrôlons manuellement les différents endpoints Rest de notre API grâce à un client d'API comme Postman ou Bruno. De cette manière nous pouvons contrôler que l'APi renvoie correctmeent les données de test.
Cette étape d'assurance quaité peut également être automatisé en prenant en compte les scénarios d'utilisation de nos endpoints que les clients d'API réalisent.
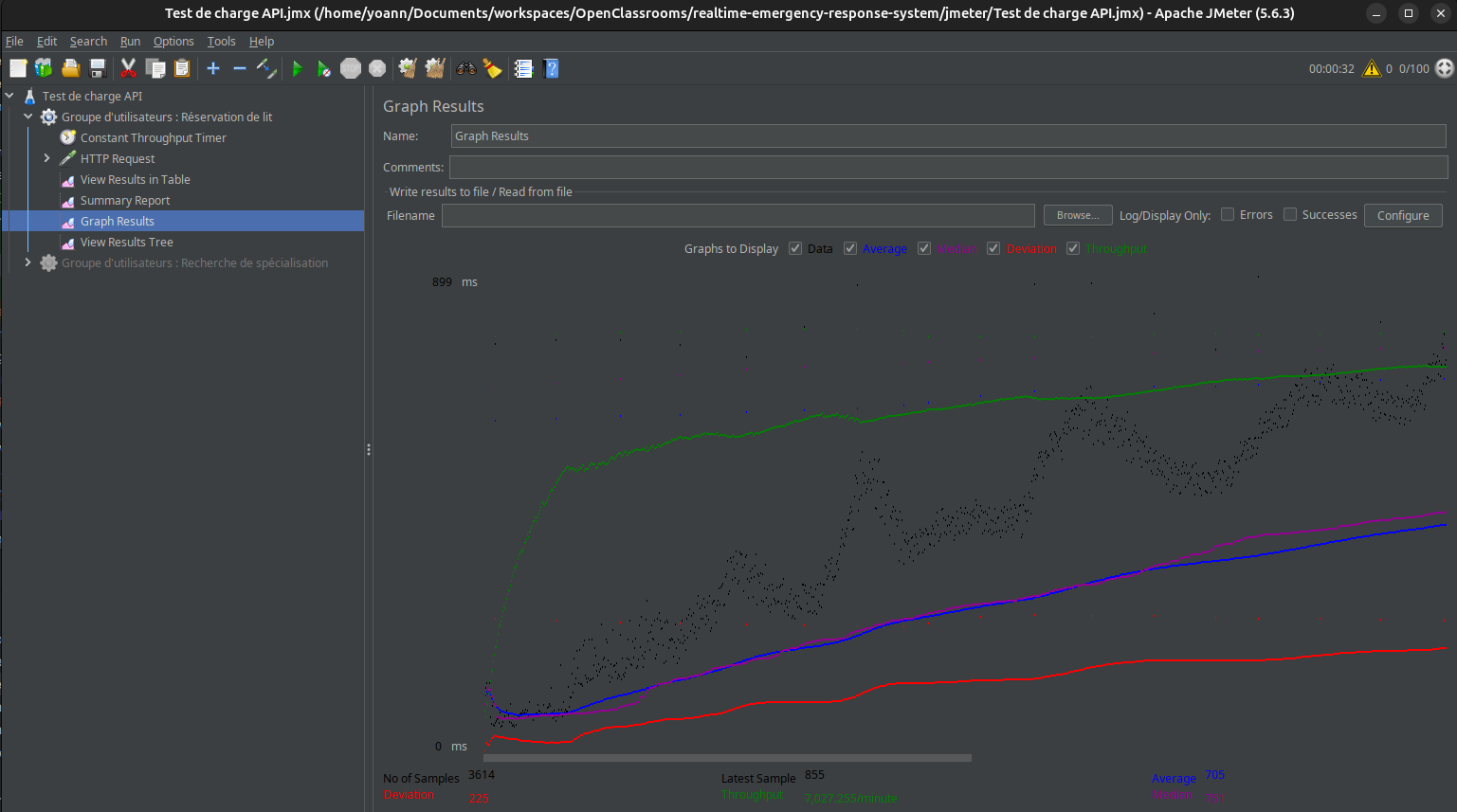
Tests de charge avec JMeter
Les tests de charge permettent d’évaluer les performances d’une application en simulant un grand nombre d’utilisateurs simultanés. Ils visent à identifier les limites de capacité, les temps de réponse et les éventuels points de défaillance.
Nous avons ajouté un fichier de confugration JMeter afin d'évaluer notre système sous la charge de 100 utilisateurs simultanés durant une période de 10 secondes.
Les enseignements tirés sont :
-
La nécessité d'un orchestrateur afin de mettre à l'échelle les services les plus sollicités
-
Implémenter une stratégie de cache afin de soulager l'usage des bases de données lorsque celles-ci renvoient souvent les mêmes données.
Test systèmes
Les tests systèmes sont les plus lents à s'éxécuter de la pyramide des tests, mais aussi les plus couteux à maintenir. Ils incluent :
-
Tests fonctionnels : Parcours utilisateurs, edge cases
-
Tests non fonctionnel : Scan dynamique de vulnérabilité,
-
Test d'UI : Non régression des éléments de l'interface graphique
Pour notre preuve de concept, ces tests n'ont pas été automatisés. n'anmoins dans la reprise des développement pour atteindre l'architecture cible, il devront être inétégrer à la stratégie de test du projet.
Exemple de test End-To-End : Réservation réussie d'un lit d'hopital (Jam.dev)
Dans une démarche d'amélioration de la qualité, nous préconisons d'intégrer rapidement des tests automatisés grâce aux framework comme Cypress, Playwright, ou encore Checkly (Monitoring-as-Code).
Note : Il convient de mettre en place un jeu de données de tests qui correspond aux données de production (anonymisées et pseudonymisées) afin de reproduire l'état du système au plus proche de sa réalité.
Pipeline d'intégration continue Github Actions
Le pipeline est déclenché lors de l'ouverture d'une pull request et se compose de plusieurs étapes : la construction, les tests et l’analyse de trois services distincts (discovery, emergency et hospital), suivies de la création et du push d’images Docker.
Chacune des étapes a été exécutée avec succès, produisant des artefacts (fichiers de build). Ce type de pipeline est essentiel pour garantir que chaque modification du code est automatiquement vérifiée, testée et prête à être déployée en production de manière fiable et rapide, réduisant ainsi les risques d’erreurs et améliorant la qualité du logiciel.
L'étape de déploiement des build dans un registry est skipped. Cependant, ces artefacts une fois stocké (en les identifiants grâce au dernier commit lié ou au numéro de version) peuvent être déployés dans des environnement de test (feature, staging) ainsi qu'en production.
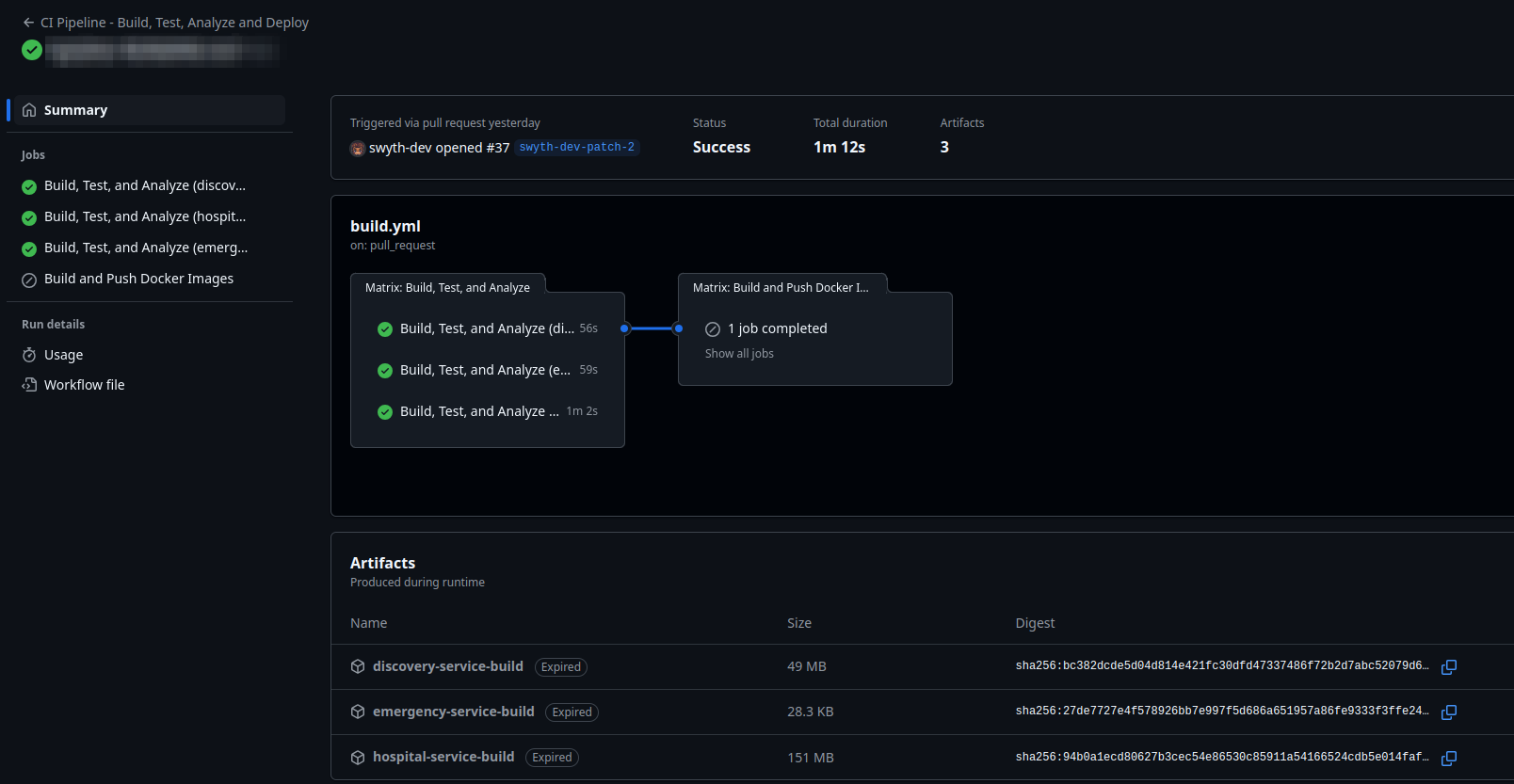
Note importante : Pour atteindre l'architecture cible, il convient de gérer correctement les variables d'environnements de chaque service, et sécuriser ceux des environnements de staging et production dans un outil de Secret Management (Hashicorp Vault, Infisical)
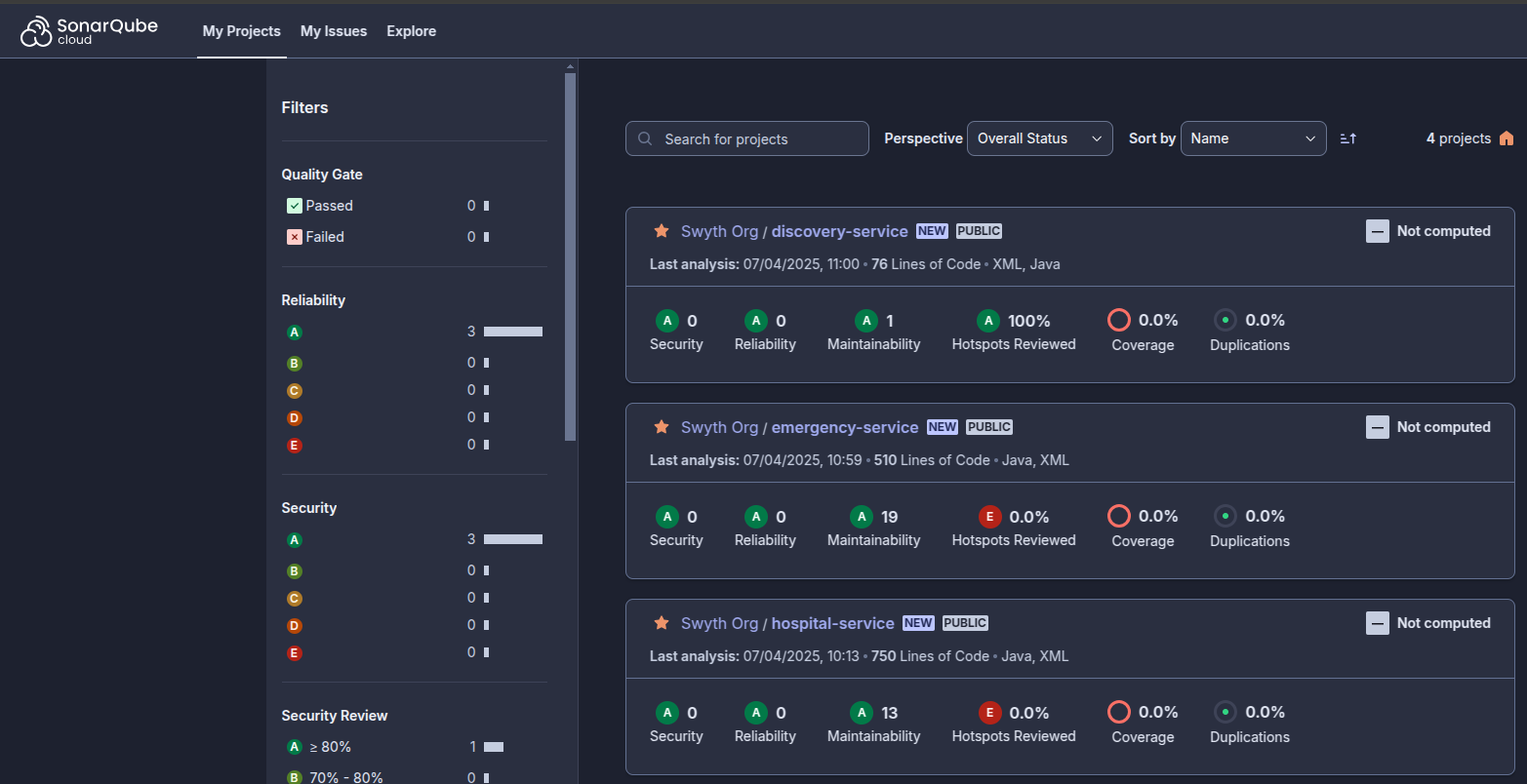
Analyse statique avec SonarQube (SAST)
Une étape importante de notre démarche qualité est l'analyse statique de sécurité. Elle a pour but de mesurer la qualité du code d’un applicatif. Pour un projet donné, il fournit des métriques portant sur la qualité du code et permet d’identifier précisément les points à corriger (code mort, bugs potentiels, non-respect des standards, manque ou surcharge de commentaires…)
L'analyse statique avec SonarQube/Cloud génère des commentaires dans les revues de Pull Request. Si les changements atteignent le niveau de qualité définit, les changements peuvent être intégrés en staging ou production, sinon le merge est bloqué. Les développeurs sont informés et prennent les mesures nécessaires afin que leurs changements passent le Quality Gate.
Bonnes pratiques
Approche Domain-Driven Design
En choissisant de découper les sous-domaine métiers en micro services, les équipes de développement peuvent concevoir les modèles en collaboration avec les équipes métiers (Business stakeholders, Product people, QA, etc)
Ainsi, les équipes de développement adopte des patterns qui assurent une haute cohérence entre les services et un faible couplage entre logique métier et implémentation technique.
Principes SOLID
Principes de conception (complémentaire à l'approche DDD) visant à créer des logiciels maintenables, compréhensibles, évolutifs et flexibles.
Documentation versionnée
-
Document d'architecture versionnés en Markdown : Les changements faits sur les documents sont traçables pour toutes les parties prenantes.
-
Les classes et méthodes des services Spring sont documentés grâce à la JavaDoc, de sorte à réduire la charge mentale des développeurs.
Intégration continue
L'intégration continue fournit un feedback rapide aux équipes de développements des changements qu'ils proposent, tout en fiabilisant la branche de production pour déployer en toute confiance et sécurité
Multiple environnement: Local, Feature, Staging, Production
Le projet se veut déployable dans de multiples environnements afin de valider la déployabilité du système avant sa mise en production.
-
Local pour les développeurs
-
Environnement éphémère à leur branche de feature/fix afin de valider grâce à des tests dynamiques les changements proposés
-
Environnement de Staging / préproduction ui reproduit l'environnement de production afin d'y intégré les derniers changements et valider le fonctionnement global du système
-
Environnement de production
Sécurité
Observations
-
La gestion des utilisateurs n'a pas été implémenté car elle n'a pas été jugée nécessaire afin de démontrer la faisabilité d'un système de réservation d'urgence. Néanmoins, dans un contexte de production, les patients seront amenés à s’authentifier avant d'être en mesure de réserver un lit d’hôpital, grâce à un composant existants du système d'information de Medhead.
-
Les données médicales, soumises à d'importantes exigences de conformité (HIPAA), ne sont pas stockées dans les systèmes mis en oeuvre par la PoC. Ces données peuvent être fournis par d'autres systèmes nationaux sans que pour autant elles ne soient stockées dans les systèmes impliqués dans le périmètre de la preuve de concept.
-
Les données personnelles liées à la réservation d'un lit sont stockées dans les systèmes liés au périmètre de la PoC. Dans des conditions réelles de production, les données des patients ou utilisateurs du service de Santé nationale sont fournies par d'autres systèmes (Identity Provider par exemple).
-
Les données personnelles telles que le nom, prénom, adresse mail, numéro de téléphone sont traités et conservés dans les systèmes liés à la PoC, mais seulement dans des environnement éphémère comme l'environnement local. Les risques d'impact sur la confidentialité ou l'intégrité des données sont alors faibles durant le traitement et le stockage, conformément RGPD.
Analyse des impacts DICT
-
Disponibilité : Grâce aux pattenr architectural microservices, les services traitant les données peuvent être mis à l'échelle. Complété par un équilibrage de charge, nos services ont une forte tolérance aux pannes, et assurent une haute disponibilité des données
-
Intégrité : En appliquant les principes SOLID à nos développements, ainsi qu'en contraignant l'accès via un service d'Authentification et d'Autorisation, les données sont modifiables seulement par les utilisateurs autorisés, garantissant un faible risque d'impact sur l'intégrité des données.
-
Confidentialité : Dans l'architecture cible, la confidentialité des données est prise en compte notamment en authorisant seulement les utilisateurs habilités à accéder aux données. De plus, les données sont chiffrées au repos de sorte à ce qu'elle ne soient pas exploitable, conformément au RGPD.
-
Traçabilité : Grâce à l'enregistrement des dates de réservations, que ce soit dans notre base de donnée mais aussi via des évènements générés, nous assurons une bonne traçabilité de la donnée au long de son cycle de vie (création modification, suppression)
Défense en profondeur
Concept venu de la sureté nucléaire, la défense en profondeur s'applique aussi aux systèmes d'informations et permet de réduire les risques d'impact sur les données. Notamment grâce à des mesures de sécurité en couche, rendant difficile la compromission totale ou partielle d'un système.
-
Certificat TLS pour assurer un chiffrement des communications (HTTPS, évènements créés et lus) entre les services, mais aussi l'extérieur
-
Sécurité applicative grâce notamment à Spring Boot Security : Cadre d'authentification et de contrôle d'accès puissant et hautement personnalisable pour les applications Spring Boot.
-
Sécurité réseau avec Proxy & Reverse Proxy : Centraliser les réponses, Filtrer les requêtes entrantes.
-
Système d'authentification centralisé
-
Autre mesure de défense :
-
Web Application Firewall, couplé à la sécurité réseau
-
Monitoring et Alerting : Supervision et alertes en temps réel en cas d'incident.
-
Security Operational Center : Dédié à la surveillance des systèmes et leurs réseaux.
Résultats et enseignements de la PoC
Conclusions
A travers cette preuve de concept, nous avons pu prouvé au consortium MedHead qu'une meilleure gestion de la réservation d'urgence est possible.
Cette PoC s'inscrit dans une vision d'intégrer facilement un nouveau système communiquant avec le reste de l'architecture d'entreprise.
A travers cette implémentation de bout en bout, Nous pourrons proposer un nouveau service réduisant considérablement le temps de réservation, tout en augmentant la qualité de service proposée aux usagers.
Enseignements
Cette preuve de concept a également servi à rendre compte de l'importance des choix de conception dans le développement de systèmes robustes et fiables.
En posant très tôt dans le projet des exigences et des bonnes pratiques, nous nous évitons une maintenance chronophage et couteuse pour faire évoluer nos systèmes et répondre rapidement aux nouveaux besoins exprimés.
La qualité entraîne la rigueur et l'organisation, et ce projet a été l'occasion de mettre en pratique les savoirs faire enseignés pour délivrer une solution répondant à des exigences d'entreprise.
Recommandations pour la mise en production
Afin d'atteindre l'architecture cible visée suite à la démonstration de cette PoC, nous préconisions certains éléments pour une mise en production réussie du nouveau système de réservation d'urgence.
-
Sécuriser les services et les communications entre les différents composants :
-
Certificats TLS pour chaque composants afin de communiquer via HTTPS
-
Chiffrement des évènements envoyés et reçu par Kafka pour sécuriser des données critiques
-
Authentification des utilisateurs sur service de résevration par un fournisseur d'identité centralisé
-
-
Compléter notre démarche DevOps en automatisant les phase de déploiement
-
Gérer les variables d'environnement pour déployer le système dans différents environnement (test, production)
-
Récupérer les artifacts (builds) de nos services pour les déployer sur un Cloud Provider
-
-
Améliorer la disponibilité et la résilience de nos systèmes
-
Intégrer un orchestrateur de conteneur pour mettre à l'échelle de manière horizontale les services les plus sollicités
-
Implémenter une stratégie de cache pour accélerer considérabement les temps de réponses pour des résultats déjà réquêtés
-
-
Monitorer les composants à l'aide d'outil de supervision déjà intégrés dans l'architecture d'entreprise de MedHead
- Installation d'agent sur les différents services afin d'envoyer les logs/événements vers un service qui les centralise (Stack ELK, Prometheus, Grafana, Loki, Mimir, Tempo par exemple)